
ChatGPT 类系统是如何运作的呢?
让我们通过下面的图解来探索它的运作机制。整个过程主要分为两大部分。
1. 训练过程。要打造一个 ChatGPT 模型,我们需要经历两个关键阶段:
- 预训练:在这一阶段,我们会对一个 GPT 模型(一种仅包含解码器的…
IT技术
(
twitter.com
)
ChatGPT 类系统是如何运作的呢?
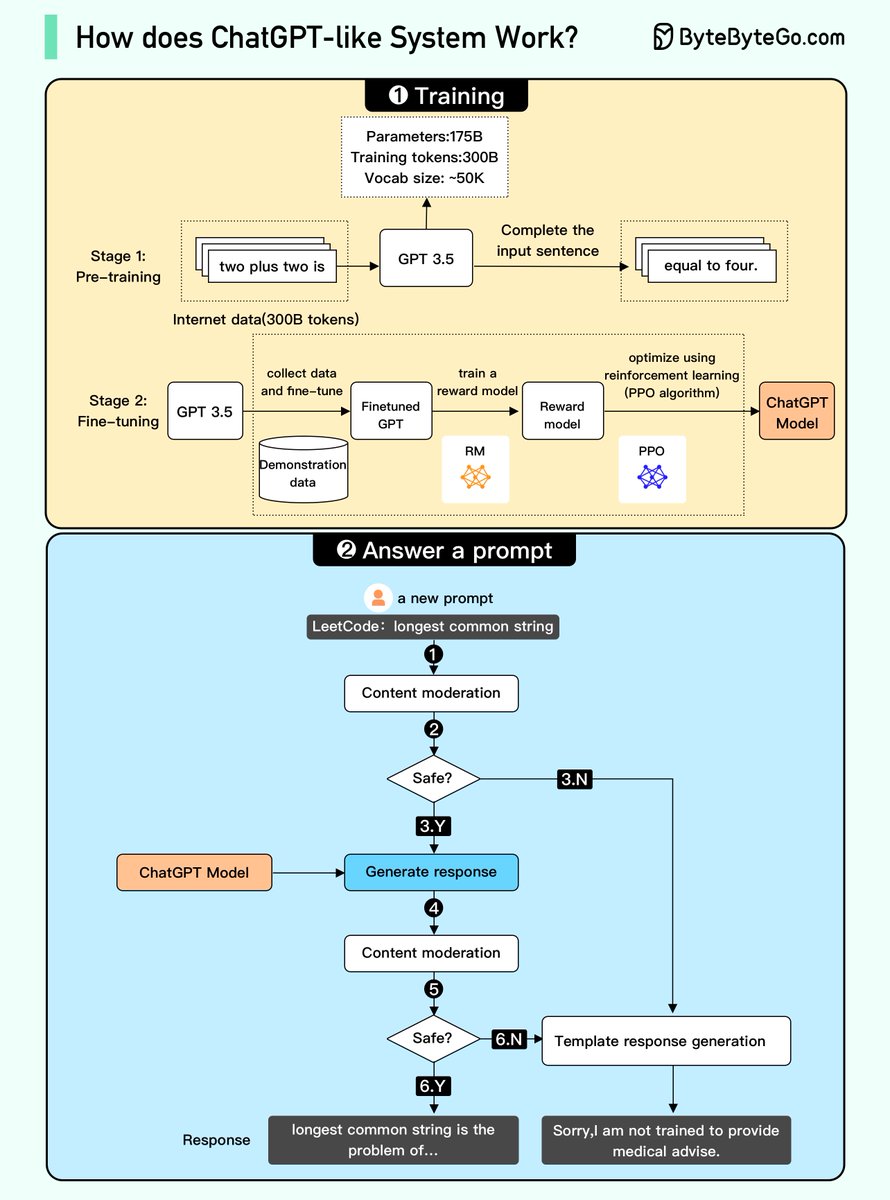
让我们通过下面的图解来探索它的运作机制。整个过程主要分为两大部分。
1. 训练过程。要打造一个 ChatGPT 模型,我们需要经历两个关键阶段:
- 预训练:在这一阶段,我们会对一个 GPT 模型(一种仅包含解码器的 Transformer)进行训练,使用大量的互联网数据。我们的目标是培养出一个能够基于已有的句子预测出下一个词汇的模型,这个预测不仅在语法上要正确,而且在语义上要与互联网上的内容相吻合。预训练阶段完成后,模型能够补全给定的句子,但还不足以应对提问。
- 微调:这一阶段是一个三步骤的过程,目的是将预训练好的模型转化为一个能够回答问题的 ChatGPT 模型:
1). 收集训练用的数据(包括问题和答案),并在这些数据上对预训练模型进行微调。模型学习如何根据问题生成与训练数据类似的答案。
2). 进一步收集数据(问题和多个答案),并训练一个奖励模型,用于将这些答案按照相关性进行排序,从最相关到最不相关。
3). 运用强化学习(PPO 优化)对模型进行微调,以提高模型回答问题的准确性。
2. 回答问题
🔹步骤 1:用户提出一个完整的问题,例如“解释一下分类算法是怎么工作的”。
🔹步骤 2:这个问题首先被送往内容审核组件。该组件确保问题不违反安全准则,过滤掉不恰当的问题。
🔹步骤 3-4:如果问题通过内容审核,它就会被送到 ChatGPT 模型处理。如果未通过审核,则直接生成模板式的回答。
🔹步骤 5-6:模型生成回答后,这个回答再次经过内容审核组件的检查。这一步骤确保所生成的回答是安全的、无害的、无偏见的等。
🔹步骤 7:如果回答通过了内容审核,它就会展现给用户。如果没有通过审核,系统则提供一个模板化的答案给用户。
点击图片查看原图

