
我在日常用 GPT-4 翻译的时候,就会发现有时候 GPT 能给出很不错的质量的翻译,但有时候质量一般甚至比较差,所以我也尝试过一次生成多个翻译结果,然后从里面人工挑选最好的翻译,但是我当时想做而没有做到的是:
如何让 GPT 从里面帮我挑选一个最好的,或者将几个的优点结合组合成一个最好的结果。…
IT技术
(
twitter.com
)
我在日常用 GPT-4 翻译的时候,就会发现有时候 GPT 能给出很不错的质量的翻译,但有时候质量一般甚至比较差,所以我也尝试过一次生成多个翻译结果,然后从里面人工挑选最好的翻译,但是我当时想做而没有做到的是:
如何让 GPT 从里面帮我挑选一个最好的,或者将几个的优点结合组合成一个最好的结果。
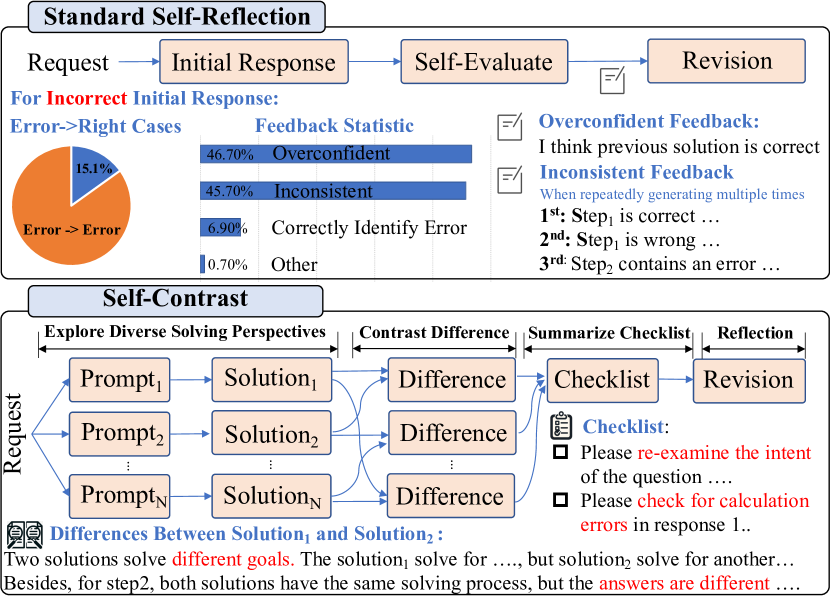
昨天读了一篇来自浙大论文《Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives》(作者之一 @spicysweet1859 )
提到的方案相对就很系统了:
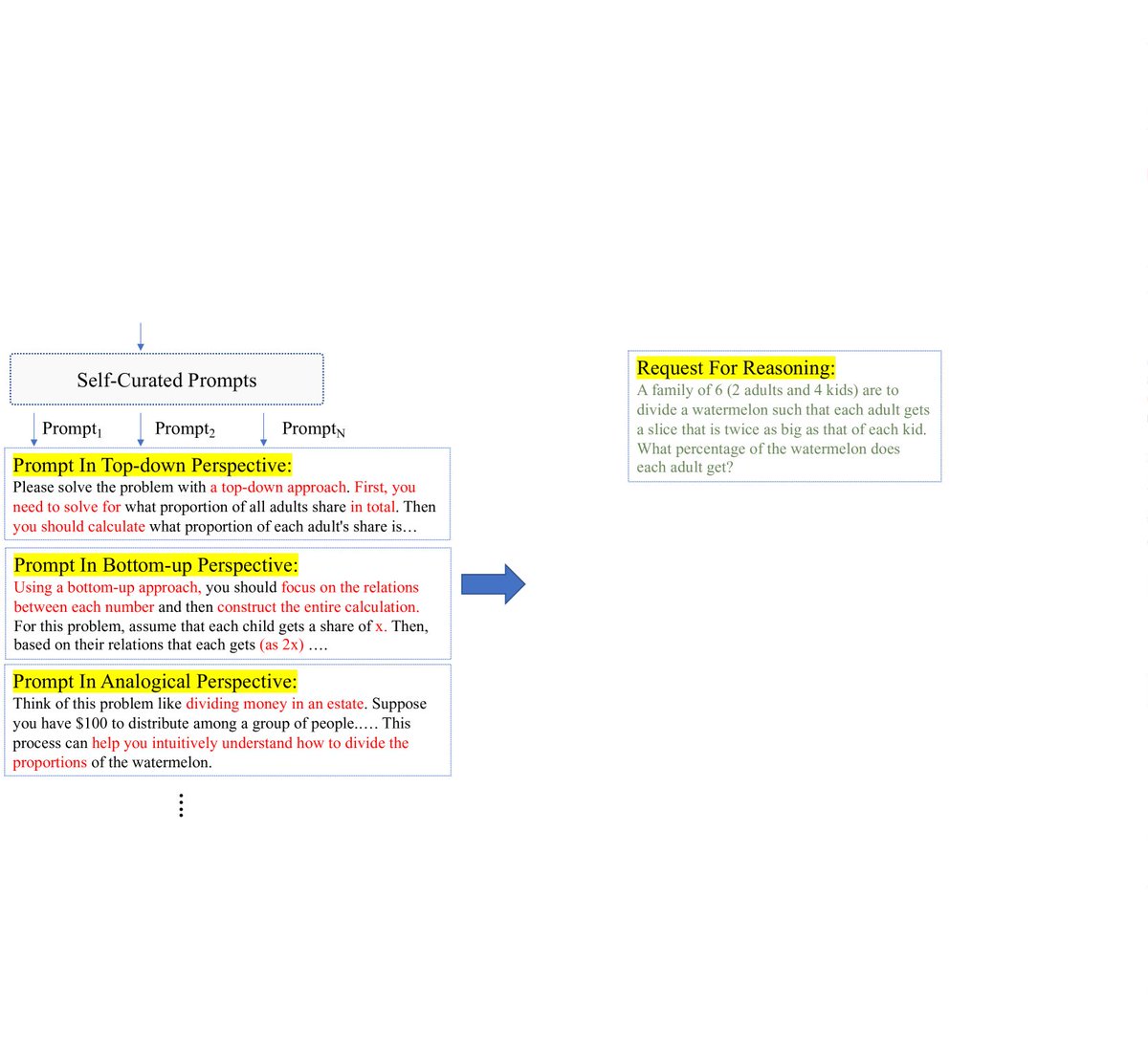
先让 LLM 根据请求生成几个不同风格的 prompt , 然后基于每一条 prompt 得到一个不同结果,然后对比这些结果之间的差异,基于这些差异总结出更有针对性的检查指令,用于反思,最后综合这些信息生成最终结果。
之所以不是直接一个Prompt生成多个结果,而是多个Prompt生成多个结果,是为了让生成的结果更多样,否则一个Prompt中的结果可能多样性不够,当然缺点是要费Token一些。但从性能上来说可能更好,因为可以并行生成。
另外对于特定任务其实不需要让LLM生成Prompt,应该人工生成Prompt效果也是一样的。
在跟作者沟通后了解到,这个方案最适合的其实不是翻译,而是推理:
> 我们这种 通过对比不同视角的responses之间的差异来启发反思的策略 对推理任务更有效果一些。 对于像翻译这类生成任务,我们实验发现其实也不需要多个视角,一个负面面视角和一个正面视角其实应该够用。这点宝玉老师您应该也介绍过。 by @spicysweet1859
推荐阅读:
https://t.co/9sjeaQ6yqq
点击图片查看原图
点击图片查看原图

