
这一轮edge端LLM前景是泡沫吗?
时隔一年,LLM小模型发展可谓每个月都有惊喜,各种尺寸越来越丰富
手机能力进步了不少,7B模型都能超过20 token/s,比去年Google发布3B小模型时候进步了太多
edge和cloud LLM应用的界限也越来越模糊,如何定义这个界限?还得看具体应用任务
这里分了几个基本场景
IT技术
(
twitter.com
)
这一轮edge端LLM前景是泡沫吗?
时隔一年,LLM小模型发展可谓每个月都有惊喜,各种尺寸越来越丰富
手机能力进步了不少,7B模型都能超过20 token/s,比去年Google发布3B小模型时候进步了太多
edge和cloud LLM应用的界限也越来越模糊,如何定义这个界限?还得看具体应用任务
这里分了几个基本场景
(如图)
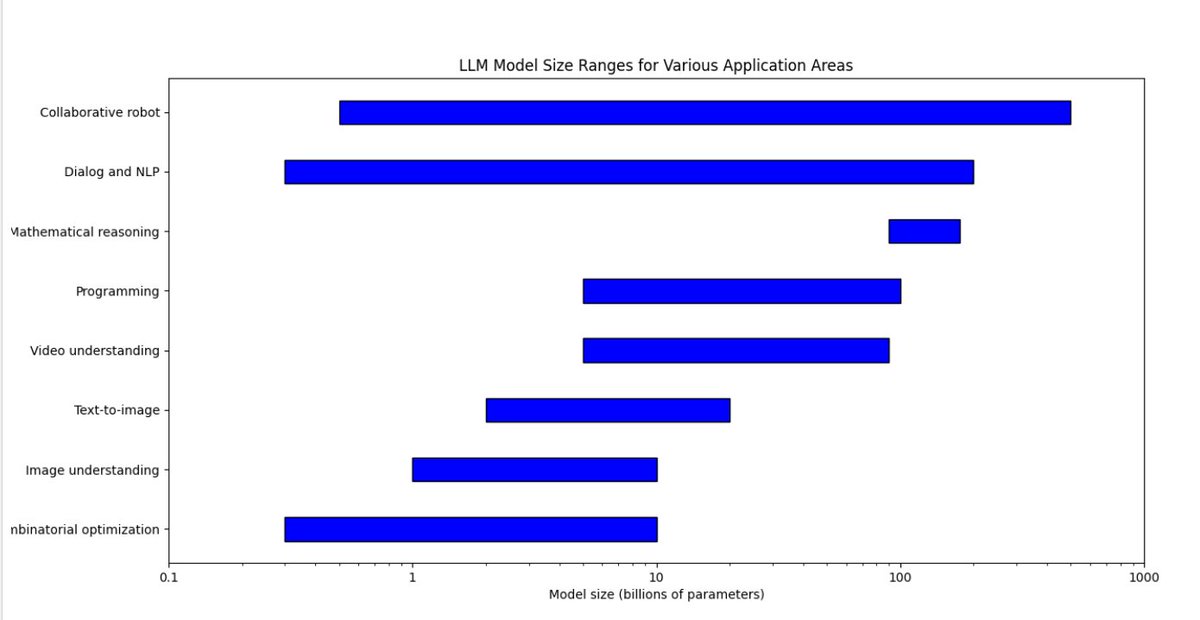
小模型和大模型参数量的效果区别,很大程度上是由错误率和幻觉率决定的,这里给的范围,属于能力到了就行,只要错误率和幻觉率达到可接受范畴,就属于在射程范围内
Edge LLM定义主要是从硬件角度划分,PC的范畴大概是20B以内,手机的范畴目前还在7B以内(旗舰能到10+B),再过两年也许能到13B.
10B以内能做到的事情,基本上就可以划为edge端手机LLM应用的范围
在Mistral和Llama 3出来之后,小模型的能力也明显上了一个台阶,我一月的时候说小模型两年内达到GPT3.5级别,现在回看起来可能是太保守了
现在按10B的参数上限来说,手机能做的事情真的挺多的,语义理解/归纳总结,有限的推理能力,常见任务分拆,文本生图,图片/视频理解,语音助手,文本填充,都在范围内,甚至FAANG大厂内部里云端一些负责分拆任务的agent也只有10B的量级
这一轮AI能力库丰富了不少,对语言和多模态的部分扩充了太多,应用组合空间上和上一轮AI热潮离手机端AI只能修图+语音识别相比,说进步了一个数量级,不为过吧
目前手机端本地LLM AI功能,主要还是单任务暂时没有什么组合,还处于简单的low hanging fruit阶段(比如最典型的语音实时翻译),甚至还远没达到Google一年前的这个探索性任务水平(见引文)
各家侧重点也略有不同,三星Galaxy S24和pixel主打的是生产力,AI笔记可以把你看过的网页提供总结,朗读网页,总结笔记。图片里的东西可以画个圈直接搜索信息。修图/修视频功能大幅提升,虽然还是不太行,得再花点时间做到adobe firefly的程度,用语音提修改要求直接修图会好点。另外开会语音自动转文字并总结这点我觉得还是有点用的
国内厂商也有快速跟进,小米(小爱6B)/Oppo(百川7B)/vivo(蓝心7B)/荣耀(百川7B)主要注意力在语音助手和文本生图(stable diffusion)。不知道苹果进入中国用文心一言效果如何。
在苹果暂时掉队的情况下,手机端侧小模型的发展,最大的阻碍还是安卓阵营的硬件/OS碎片化,任何一个app想要适配安卓阵营各种千奇百怪的AI NPU加速器,简直是噩梦
各大手机厂商这一年来做出的edge端大模型应用的尝试,还不是很多毕竟发展时间有限,但不少概念还是很不错的,Google的Gemini小模型越来越强力,安卓阵营的语音助理的泛化能力和协同各个app的能力以后必然会大幅拓展。
PC端扩点内存跑20B模型(量化后12GB),能干的事情只会更多更丰富。至于更多第三方端侧大模型app的发展,可能得等Llama3/4以及Mistral来打开更多想象空间了
点击图片查看原图

