
# AI 开源模型分享
最强语音识别和说话人分离模型
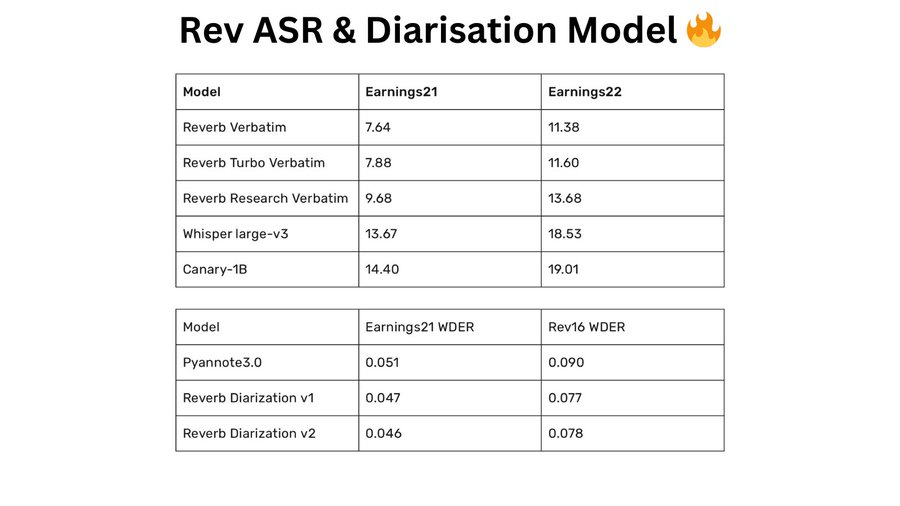
Reverb 推出最强开源语音识别 (ASR) 和说话人分离 (Diarization) 模型, 评测结果击败 OpenAI 推出的 Whisper large-v3!
# Reverb ASR 模型
- 使用 20 万小时的人工转录数据训练
- 达到了最新的词错误率 (WER) 水平
- 支持可定制的逐字转录
#
时政
(
twitter.com
)
# AI 开源模型分享
最强语音识别和说话人分离模型
Reverb @rev 推出最强开源语音识别 (ASR) 和说话人分离 (Diarization) 模型, 评测结果击败 OpenAI 推出的 Whisper large-v3!
# Reverb ASR 模型
- 使用 20 万小时的人工转录数据训练
- 达到了最新的词错误率 (WER) 水平
- 支持可定制的逐字转录
# 模型架构
- 采用 CTC/attention 架构
- 包含 18层 conformer 和 6 层 transformer
- 约 6 亿参数
- 具有控制逐字输出的特定语言层
# 推理能力
- 支持多种解码模式: CTC、attention 和联合 CTC/attention 解码
- 生产环境就绪, 包括 WFST 束搜索、单字语言模型和 attention 重新评分
- 使用并行处理和后处理以提高效率
# Diarization 模型
- 基于 pyannote 框架, 使用 2.6 万小时标注数据进行微调
- v1 版本基于 pyannote3.0 架构, 有 2 个 LSTM 层, 220 万参数
- v2 版本是更先进的版本, 用 WavLM 替代了 SincNet 特征, 提供更精确的说话人分离
# 开源模型地址
https://t.co/AM7W8fh7FY
# 在线体验地址
https://t.co/g3Sgfil2Vy
点击图片查看原图

