
让 AI 模型"轻装上阵":Ollama 新功能让内存消耗大幅降低
「 通过一项新技术实现了显著降低 AI 模型运行内存需求的突破,让普通电脑也能运行更大、更强大的 AI 模型,同时基本不影响模型的输出质量」
核心功能与意义:
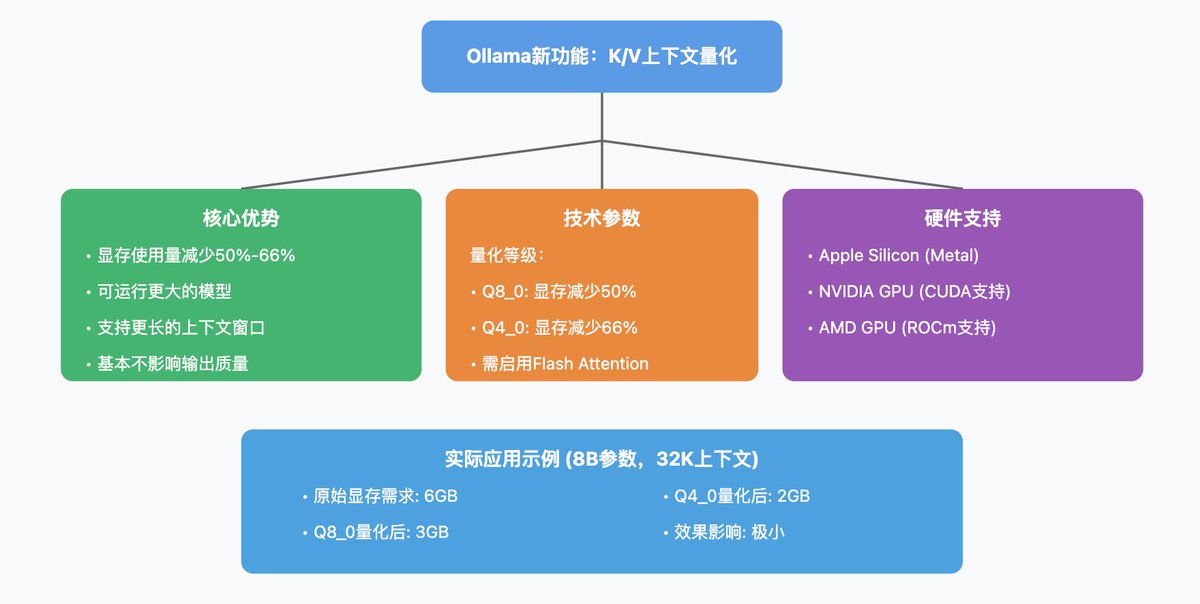
- K/V 上下文缓存量化可以显著减少 VRAM (显存)使用量
- 使用 Q8_0
时政
(
twitter.com
)
让 AI 模型"轻装上阵":Ollama 新功能让内存消耗大幅降低
「@ollama 通过一项新技术实现了显著降低 AI 模型运行内存需求的突破,让普通电脑也能运行更大、更强大的 AI 模型,同时基本不影响模型的输出质量」
核心功能与意义:
- K/V 上下文缓存量化可以显著减少 VRAM (显存)使用量
- 使用 Q8_0 量化可以将上下文所需显存减少约 50%
- 使用 Q4_0 量化可以减少约 66% 的显存使用(但会略微影响质量)
主要优势:
- 能够运行更大的模型
- 可以扩展上下文窗口大小
- 减少硬件资源占用
具体示例:
对于一个 8B 参数、32K 上下文窗口的模型:
- F16 K/V: 需要约 6GB 显存
- Q8_0 K/V: 需要约 3GB 显存
- Q4_0 K/V: 需要约 2GB 显存
使用方法:
- 需要使用最新版本的 Ollama
- 需要启用 Flash Attention (OLLAMA_FLASH_ATTENTION=1)
- 通过设置环境变量 OLLAMA_KV_CACHE_TYPE="q8_0" 来启用
硬件支持:
- 支持 Apple Silicon (Metal)
- 支持 NVIDIA GPU (需要 CUDA 支持,Pascal 及更新架构)
- 支持大多数 AMD GPU (通过 ROCm,但支持可能不如 CUDA 完善)
质量影响:
- Q8_0: 对普通文本生成的质量影响极小,适合大多数用户
- Q4_0: 有一些明显的质量降低,但对于显存受限的情况下仍然可用
点击图片查看原图

