2
1
0

如果你要对Markdown的翻译做到结构一致,即使让 LLM 翻译时采用双语对照,也会可能遗漏,所以这类需求你不能完全依赖于 LLM,必须要结合程序来做,把文本解析成结构化的数据,这样才好校对是不是有遗漏。
IT技术
(
twitter.com
)
由
宝玉
提交
如果你要对Markdown的翻译做到结构一致,即使让 LLM 翻译时采用双语对照,也会可能遗漏,所以这类需求你不能完全依赖于 LLM,必须要结合程序来做,把文本解析成结构化的数据,这样才好校对是不是有遗漏。
比如需要先对Markdown解析,解析成结构化的树状结构,然后从中提取出需要翻译的文本节点,给每个节点分配一个唯一ID(翻译后好对应回去),再分块去调用 LLM 翻译,返回结构化的XML或者JSON结果,翻译后再根据ID将翻译结果写回节点,并且可以用程序校验节点有无遗漏。
但这样做的问题是翻译结果可能不流畅,至于解决方案么,卖个关子当做个思考题🤓
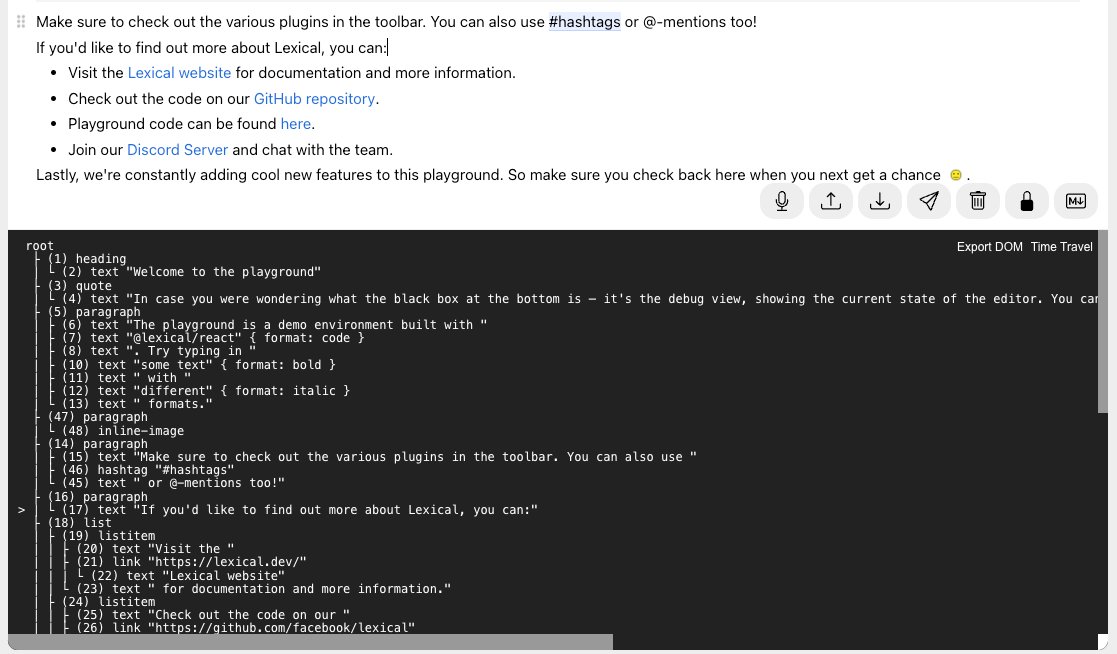
注:截图为 lexical 编辑器的 Playground,只是用来可视化说明 Markdown 解析后结果
点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
4
334
333
333
10
197
196
196
17
115
114
114
18
80
79
79
19
142
141
141

