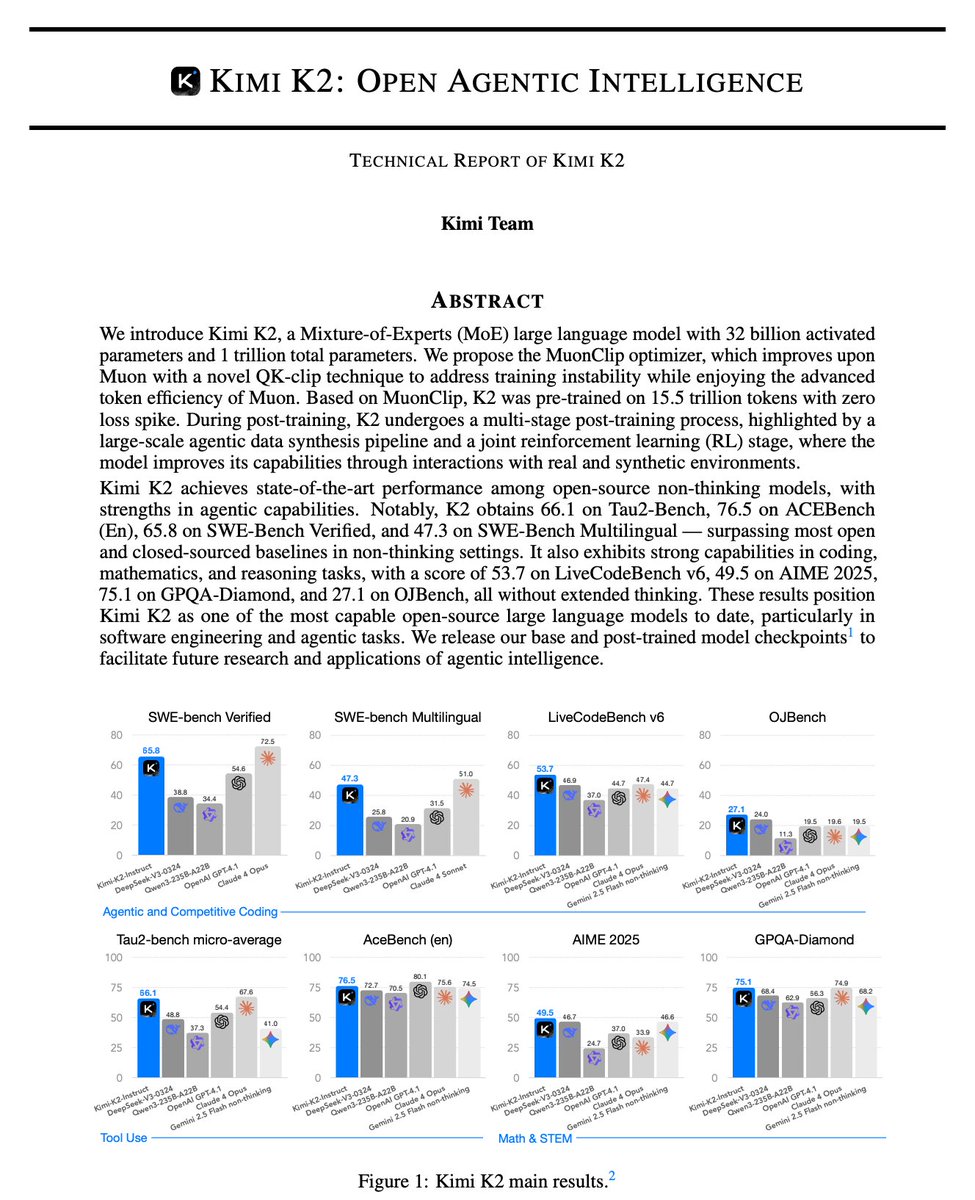
2
1
0

K 2 的技术报告也发布了
专家数量:384个专家,每次前向激活8个,提升了稀疏性和性能。
注意力机制:采用多头潜在注意力(MLA),隐藏维度7168,注意力头数64(相比同类模型减少一半,提升长文本推理效率)。
IT技术
(
twitter.com
)
由
歸藏(guizang.ai)
提交
K 2 的技术报告也发布了
专家数量:384个专家,每次前向激活8个,提升了稀疏性和性能。
注意力机制:采用多头潜在注意力(MLA),隐藏维度7168,注意力头数64(相比同类模型减少一半,提升长文本推理效率)。
优化器:创新性地提出了MuonClip优化器,将高效的Muon算法与QK-Clip权重裁剪机制结合,解决了大规模训练中的不稳定问题,防止注意力logit爆炸。
数据处理:预训练数据覆盖Web文本、代码、数学和知识四大领域,采用合成重写(rephrasing)技术提升token利用率,尤其在知识和数学领域通过多样化重写增强泛化能力。
训练规模:预训练总计15.5万亿高质量token,采用4096-token上下文窗口,后期通过YaRN方法扩展到128k上下文。
稀疏性Scaling Law:实验表明,在激活参数数固定的情况下,增加专家总数(提升稀疏性)能显著降低训练和验证损失,提升模型表现。
推理优化:减少注意力头数,降低长文本推理的计算开销,提升实际应用效率。
硬件:基于NVIDIA H800 GPU集群,采用多级并行策略和高效的激活存储与重计算技术,保证大模型训练的可扩展性和稳定性。
点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
1
539
538
538
10
155
154
154
12
214
213
213
15
209
208
208
16
500
499
499
19
250
249
249

