2
1
0

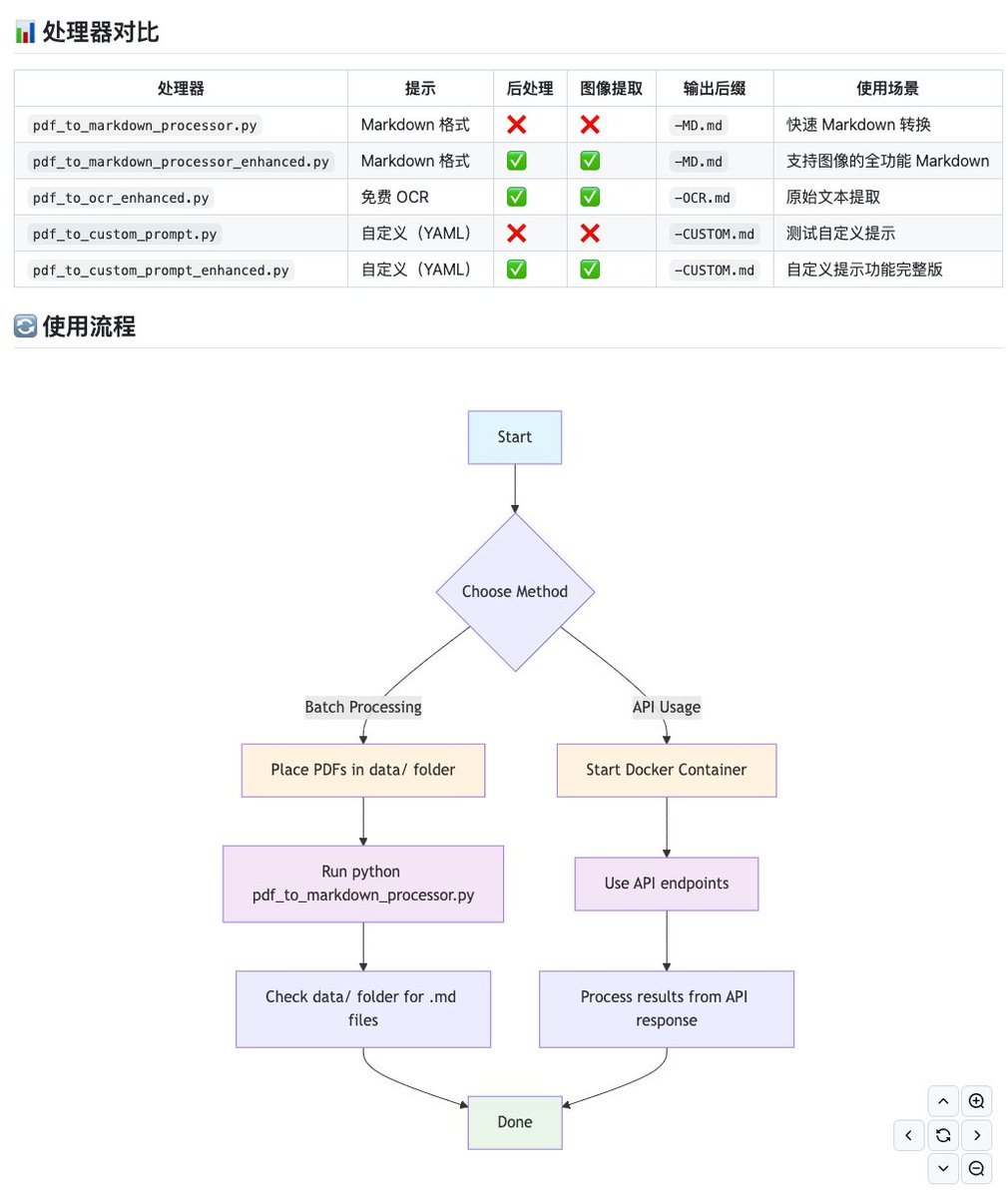
有位开发者,基于 DeepSeek-OCR 模型,做了一个高质量的 PDF 文档转 Markdown 文件的开源工具。
不仅能准确地识别文档内容,还能完整保留原始格式结构,以及自动提取文档中的图片。
GitHub:
支持标准化的 Markdown 转换、纯 OCR
时政
(
github.com
)
由
GitHubDaily
提交
有位开发者,基于 DeepSeek-OCR 模型,做了一个高质量的 PDF 文档转 Markdown 文件的开源工具。
不仅能准确地识别文档内容,还能完整保留原始格式结构,以及自动提取文档中的图片。
GitHub:https://t.co/eW18KhTWvr
支持标准化的 Markdown 转换、纯 OCR 提取和自定义提示词处理等多种模式,以及批量处理多个文档。
通过 Docker 部署使用,并配备完整的 REST API 接口方便集成,注意电脑的显卡至少要 12GB 显存。
点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
1
35
34
34
2
318
317
317
9
174
173
173
12
353
352
352
17
18
17
17
19
115
114
114
20
125
124
124
21
144
143
143

