
通义发布的 DeepResearch Agent 六篇论文我都看完了,最喜欢的一篇是《WebWeaver》,它压缩上下文的方法非常有启发,所有需要 AI 长文写作的场景都可以参考。
一般让 AI
时政
(
twitter.com
)
通义发布的 DeepResearch Agent 六篇论文我都看完了,最喜欢的一篇是《WebWeaver》,它压缩上下文的方法非常有启发,所有需要 AI 长文写作的场景都可以参考。
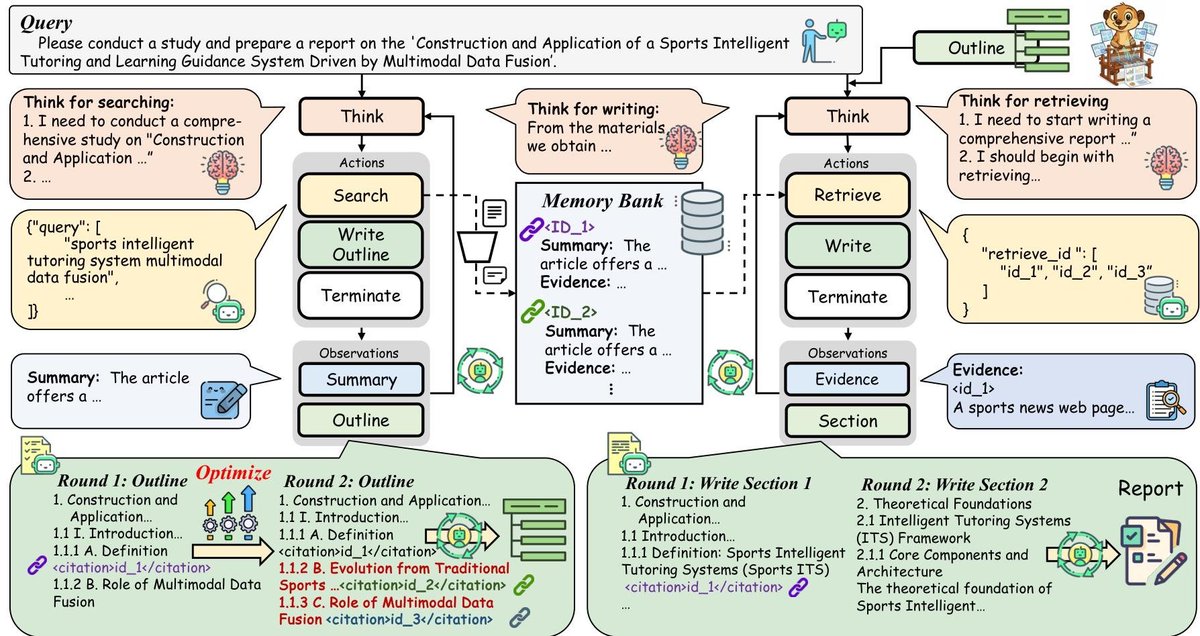
一般让 AI 写长文都是把资料一股脑放到上下文里面,这会导致模型注意力错乱,因为参考的资料太多,上下文太长,模型不可避免会忽略一些重要信息或者被无关信息误导。
WebWeaver 的解法是分而治之,在写作大纲里面放入引用的资料 id,然后让模型一个个章节写,写每个章节的时候都只提供当前这个章节的资料,这样就避免了上下文太长的问题,保护了模型的注意力。
上面的写作过程也是 Agentic 的,不需要硬编码让模型按顺序写,而是直接把整个大纲提供给它,让它自己调用查询资料的工具一步步写出来。这里还有个压缩上下文的技巧是在写最新的章节的时候,把之前的章节的资料都隐藏,只保留写作结果,这样模型既有全局的信息,又能节省上下文。
大纲示例
```
1. Hoehn and Yahr Scale Classifications
```
资料查询工具示例
```
{"name": "retrieve", "arguments": {"url_id": ["id_2", "id_6", "id_9", "id_12", "id_13", "id_14", "id_15",
"id_17", "id_20", "id_21"], "goal": "Gather comprehensive information about Hoehn and Yahr scale
classifications and disease staging systems for Parkinson’s disease"}}
```
这种利用查询工具传递 id 的方式来压缩上下文,我在 DeepResearch 的阅读工具里面也用过,主要是用来减少模型生成 url 比较慢的问题,但用在写报告的阶段我确实没想到,对我很有启发。
但这种 Agentic 的方式相比用 Workflow 的方式效果好多少,我是存疑的,因为你让模型自己调用FunctionCall 可能会有幻觉,用代码的方式手动解析大纲然后用 Workflow 的方式可能更可靠。后续我也会做实验对比看看。
点击图片查看原图

