
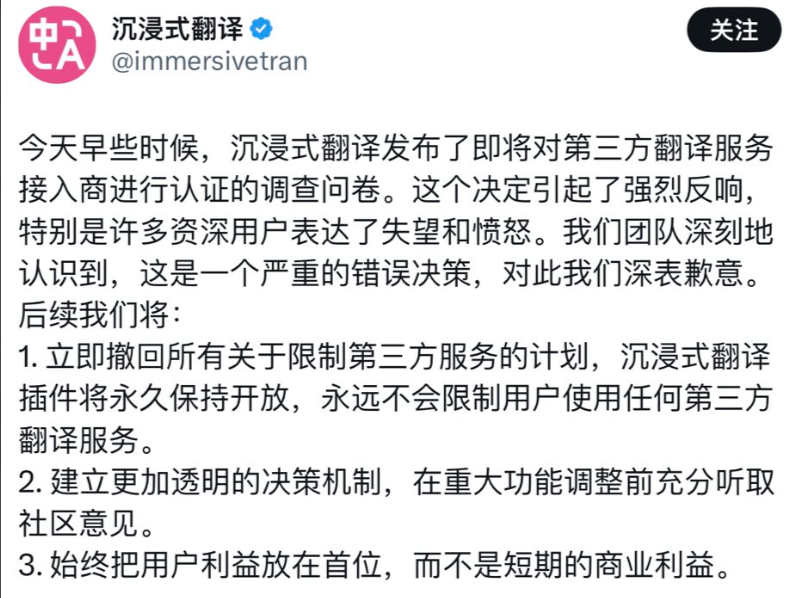
最近《沉浸式翻译泄漏隐私》 的话题火了,今天就借着这个热点,聊聊如何对带有用户生成内容(UGC)的工具进行基础的Technical SEO,最大化页面收录效果。
为什么UGC内容容易被搜索引擎收录?
时政
(
twitter.com
)
最近《沉浸式翻译泄漏隐私》@immersivetran 的话题火了,今天就借着这个热点,聊聊如何对带有用户生成内容(UGC)的工具进行基础的Technical SEO,最大化页面收录效果。
为什么UGC内容容易被搜索引擎收录?
以《沉浸式翻译》为例,所谓的“隐私泄漏”往往是因为用户主动将内容分享到不同平台,导致URL被搜索引擎爬虫发现并收录。类似的情况也出现在Grok的聊天分享(可用 site:https://t.co/kYjXer3Sst 查看收录情况)和ChatGPT的共享聊天功能(ChatGPT一度允许谷歌收录共享内容,但随后通过noindex和robots.txt阻止了爬虫)。
要让页面被搜索引擎收录,需满足以下条件:
1. 爬虫能发现页面URL。
2. 网站未屏蔽对应的爬虫。
3. 页面通过meta robots标签允许收录。
4. 搜索引擎对该域名有足够的爬虫预算。
5. 页面内容质量符合搜索引擎的标准和政策。
前三个条件可由网站主动控制。如果不想让内容被收录,可以:
防止URL被爬虫嗅探到。
在robots.txt中屏蔽对应URL路径。
在页面中设置meta robots为noindex。
如何利用UGC内容提升网站流量?
UGC内容可以为网站带来流量,但直接开放所有UGC内容给搜索引擎可能带来以下问题:
爬虫预算消耗:大量UGC内容会占用搜索引擎分配给网站的爬虫资源。
话题分散:UGC内容主题不可控,可能导致搜索引擎无法准确判断网站的核心主题,影响排名。
因此,除非你的网站权重极高(例如DR超过80),否则不建议完全开放UGC内容给搜索引擎。
更好的做法是:
筛选优质UGC内容:只开放高质量、与网站主题相关的内容供爬虫收录。(参考Notion/Perplexity)
优化SEO设置:确保URL结构清晰、使用合适的meta标签、避免重复内容。
控制爬虫行为:通过robots.txt和noindex精准管理哪些内容可被收录。
点击图片查看原图

